
What is search? Suppose there is a large corpus of documents, and the goal is to find the subset of those documents relevant to some query. Search is the process of surfacing those relevant documents.
What is visual search? In this project, the corpus is a video (two episodes of Friends), the documents are images, and the query is an image or a cropped region of an image.
Traditional search is done with text. My implementation of visual search borrows many ideas from text search. To understand how visual search works, it is helpful to first understand how text search works.
The high level idea is to convert each document into a vector of real numbers in some meaningful feature space, and then rank each document against the given query by comparing their respective feature vectors.
One common feature space for text search is called "bag of words." It is simply a count of how many times each word appears in the document. One limitation with this representation is it does not capture grammar or the relative order of words.
Words like "like", "and", and "are" are common to many documents but don't provide much meaning. These words are called "stop words." It is common practice to exclude them from the bag of words model. This improves relevancy by reducing the similarity between the query and irrelevant documents.
It is also helpful to give each word a different weight based on how rare it is among the corpus. One way to compute such a weighting is to use "term frequency-inverse document frequency" (TF-IDF). Simply put, if a word appears many times in a given document, it's value will be higher. Conversely, if the word appears in many documents, its value will be lower. This is a way of normalizing to word frequency across documents.
A relevancy score is assigned to each document by comparing its feature vector with the query's feature vector. There are many similarity metricts to choose from. Some common ones are dot product, cosine similarity, and euclidean distance. All documents are sorted by relevancy score, and the top N of them are returned as search results.
The high level idea is to convert each image into a bag of visual words, and then use the same bag of words method used for text search.
The first step is to compute the visual vocabulary offline. I use SIFT to identify small, descriptive patches in the image. Many of these patches look similar. I want to group similar patches together and consider them to be the same visual word. I acheive this by applying k-means clustering to the SIFT feature vectors. The number of clusters is a free paramter. I used k = 1500. This means my vocabualry has 1500 visual words.

Just like with text, some visual words are very common and mostly meaningless. I declare the most common visual words to be stop words and exclude them.
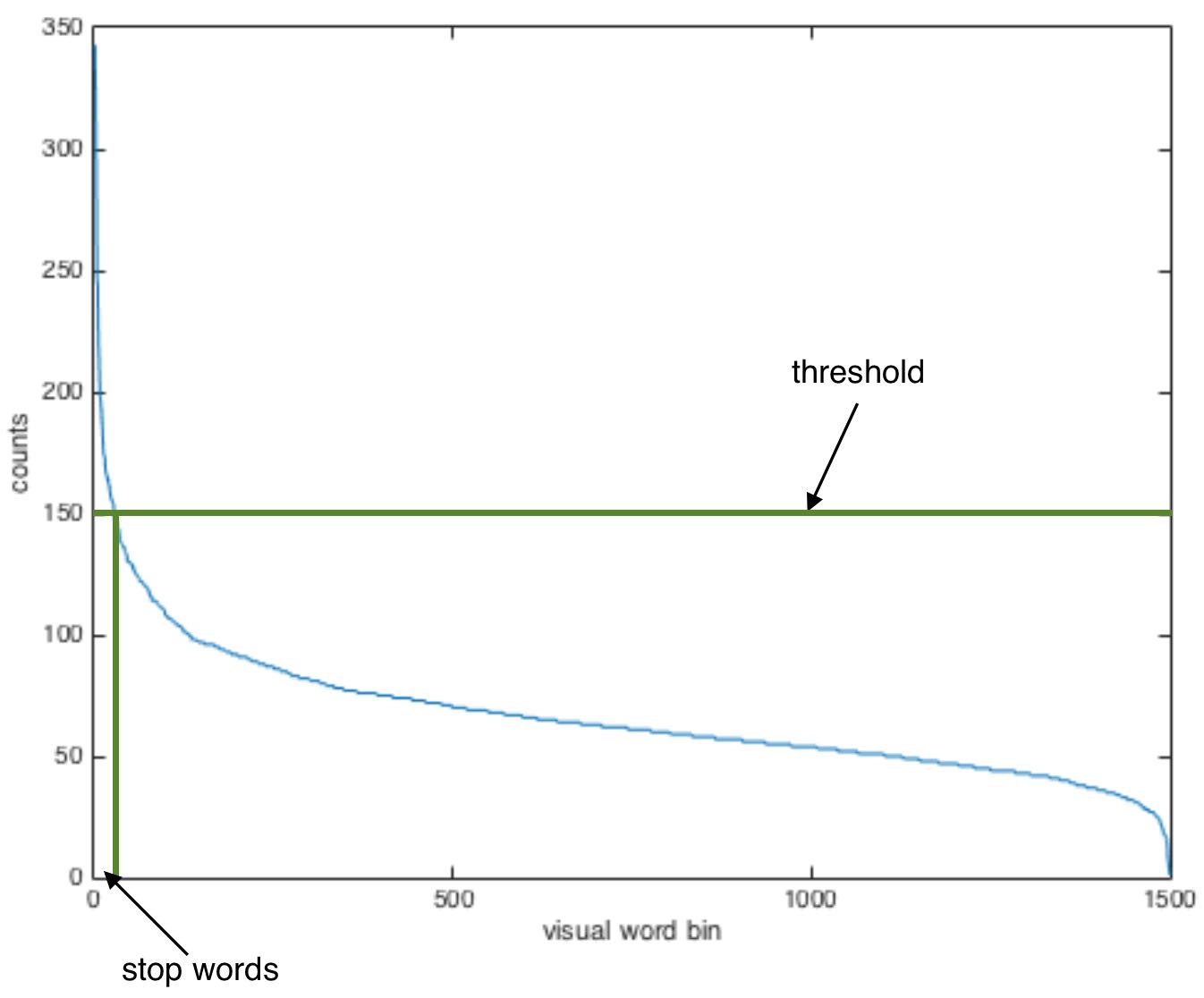
Now treat visual words the same as text words. An image can be represented as a histogram that counts the requency of each visual word in the image. We can even use the same TF-IDF weighting algorithm.
At query time (online), run the SIFT descriptor over the query image. Map each response patch to a visual word by nearest neighbors among the k cluster centers. This can be sped up using hierarchical clustering trees. From here, the process is identical to text search!


For this first example, I used the whole image as the query. All returned images include the same red couch, and the first 4 include the same subject. The 5th image shows different people on the same couch and with the same white object in the background. All the images are similar yet not nearly-identical (with the exception of 2 and 4), which is a pleasing result.


For this example, the query was the cropped region around the word "producers," shown in red. All of the top 5 results contain either the word "producers" or "producer."
This example shows how stop words can affect search results. The query is the cropped region shown in green. It contains the objects on the coffee table.

The top three results with stop words are shown on the left, and the top three without stop words are shown on the right. It looks to me like relevancy is better without stop words, which is what I expected.

